Pré-processamento do documento#
Vamos considerar a criação de um modelo usando o exemplo do documento "Relatório de custo de trabalhos realizados e despesas".
Antes que o robô comece a criar o modelo, o documento deve ser reconhecido pelo robô e salvo no caminho especificado.
Por exemplo, ao reconhecer um documento no formato .pdf no projeto do script, adicionamos o bloco "Obter texto da página OCR". Nas configurações de resultados na aba "Saída", indicamos $DocPageText
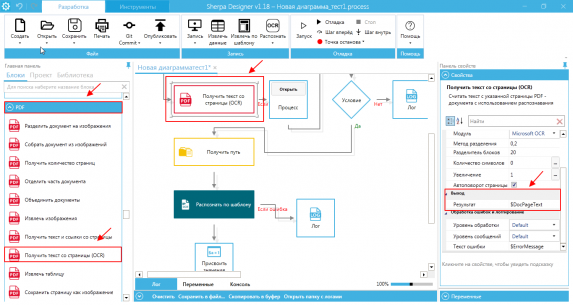
É importante entender que em alguns arquivos reconhecidos, o nome das colunas das tabelas pode não coincidir com os nomes das colunas que são definidos para a saída do robô. Além disso, algumas colunas podem estar completamente ausentes ou algumas bordas das tabelas podem estar faltando.
Verificar e mapear os nomes das colunas é necessário no script do projeto "Definir colunas.process", que são definidos nas configurações à direita: "Painel de propriedades" — "Variáveis".
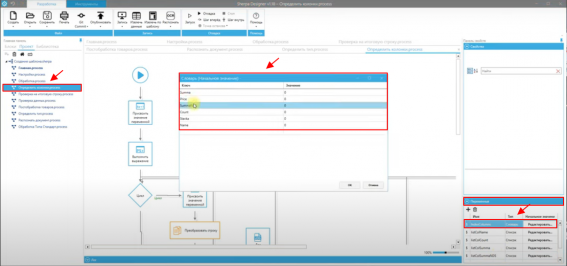
Por exemplo, após o processamento do documento "Relatório de custo de trabalhos e despesas", o robô deve gerar as seguintes colunas:
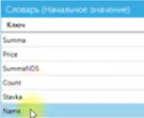
| Summa | total |
| Price | preço |
| SummaNDS | total com IVA |
| Stavka | taxa |
| Name | nome/título |
| Count | quantidade |
Mas ao criar o modelo, vemos que no próprio documento parte desses dados está ausente.