Trabalhando com documentos de várias páginas#
Ao criar modelos para documentos de várias páginas, é necessário definir âncoras exclusivas, cuja busca será realizada apenas em um determinado tipo de documento. Por exemplo, em um documento UPD pode aparecer a palavra nota fiscal, portanto, não é necessário usar essa palavra como âncora nem para UPD, nem para Nota Fiscal.
Quando necessário trabalhar com um documento de várias páginas, pode acontecer que um documento esteja em várias páginas.
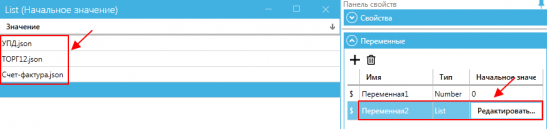
Para cada tipo de documento, é necessário criar um modelo separado (por exemplo, 1 — Torg12, 2 – Nota Fiscal, 3 – UPD) e indicar todos os tipos de documentos nos valores da variável. Nesse caso, o tipo da variável deve ser escolhido como Lista.
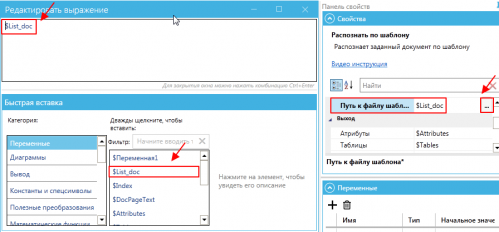
Em seguida, indicamos o caminho para o arquivo do modelo:
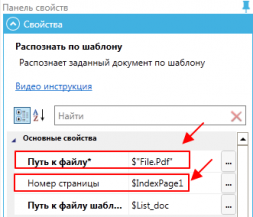
Indicamos o Número da página – 1, para que o reconhecimento comece pela primeira página. Também indicamos o caminho para o arquivo.
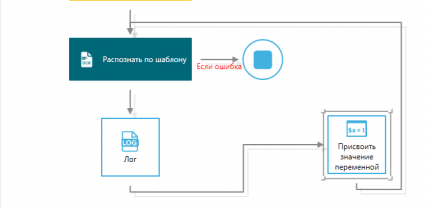
Finalizando o trabalho do robô em caso de erro
Após a conclusão do trabalho de criação do modelo, é necessário descrever o próximo cenário para seu reconhecimento e saída de resultados.
Se o robô não conseguir realizar o reconhecimento do documento, o cenário pode ser interrompido. Para isso, no Sherpa Designer, adicionamos o bloco "Fim". Também é possível adicionar um bloco "Log" para registrar o erro no log.


Um erro de reconhecimento pode ocorrer em casos em que nenhum dos modelos se adequou ou quando não restam documentos para reconhecimento.
Caso haja vários documentos no arquivo PDF, e um dos tipos de documentos seja desconhecido para o robô (ou seja, não há modelo para esse tipo de documento), o robô irá ignorar esse documento e reconhecerá apenas aqueles para os quais existem modelos.
Buscando o segundo e os subsequentes documentos em um arquivo de várias páginas
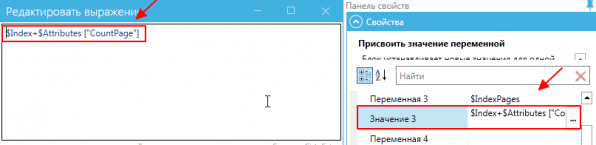
Depois que um dos modelos foi reconhecido em um documento de várias páginas, é necessário fazer alterações no índice descrito (adicionar), para que o reconhecimento subsequente não comece na próxima página, mas após o documento encontrado.
Como nos atributos existe o parâmetro CountPage, que corresponde ao número de páginas envolvidas no reconhecimento pelo modelo, para continuar o processo de reconhecimento, é necessário adicionar esse parâmetro ao índice.
Assim, se no documento de várias páginas o primeiro documento, que ocupa várias páginas, foi reconhecido, ao adicionar o parâmetro CountPage, o reconhecimento subsequente começará na página seguinte ao documento reconhecido.
Depois disso, configuramos o cenário para o reconhecimento repetido do documento.