Preprocesamiento del documento#
Consideremos la creación de una plantilla utilizando como ejemplo el documento "Informe sobre el costo de los trabajos realizados y gastos".
Antes de que el robot comience a crear la plantilla, el documento debe ser reconocido por el robot y guardado en la ruta especificada.
Por ejemplo, al reconocer un documento en formato .pdf en el proyecto de script, añadimos el bloque "Obtener texto de la página OCR". En la configuración de resultados en la pestaña "Salida", indicamos $DocPageText
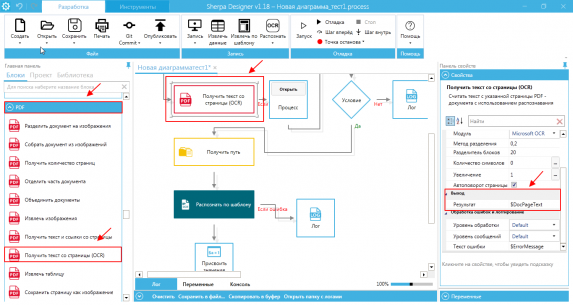
Es importante entender que en algunos archivos reconocidos, el nombre de las columnas de las tablas puede no coincidir con los nombres de las columnas que se han definido para la salida del robot. También puede que algunas columnas estén completamente ausentes o que falten algunos bordes de las tablas.
Es necesario verificar y comparar los nombres de las columnas en el script del proyecto "Definir columnas.process", que se establecen en la configuración a la derecha: "Panel de propiedades" — "Variables".
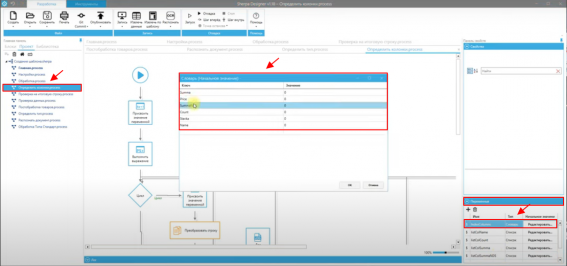
Por ejemplo, después de procesar el documento "Informe sobre el costo de los trabajos y gastos", el robot debe generar las siguientes columnas:
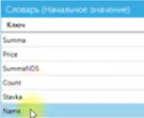
| Summa | suma |
| Price | precio |
| SummaNDS | suma con IVA |
| Stavka | tasa |
| Name | nombre/título |
| Count | cantidad |
Pero al crear la plantilla, vemos que en el propio documento falta parte de estos datos.